 Sparrow Robotics
Sparrow RoboticsCaffeinated Machine Learning

Caffeinated Machine Learning
When trying to wrap your head around Machine Learning it's good to start simple.
I really like coding. What's interesting, when I first start in the morning it's kinda slow, before I warm up and it's not really about the sunlight, as it works about the same in every season.
One interesting correlation I found was the consumption of mildly caffeinated beverages. The more coffee cups I drank, the better my code was. The better my code was, the more crap I crossed out of my TODO list.
So I plotted my coffee cups and my code quality, ran the linear regression on it and… it didn't work.
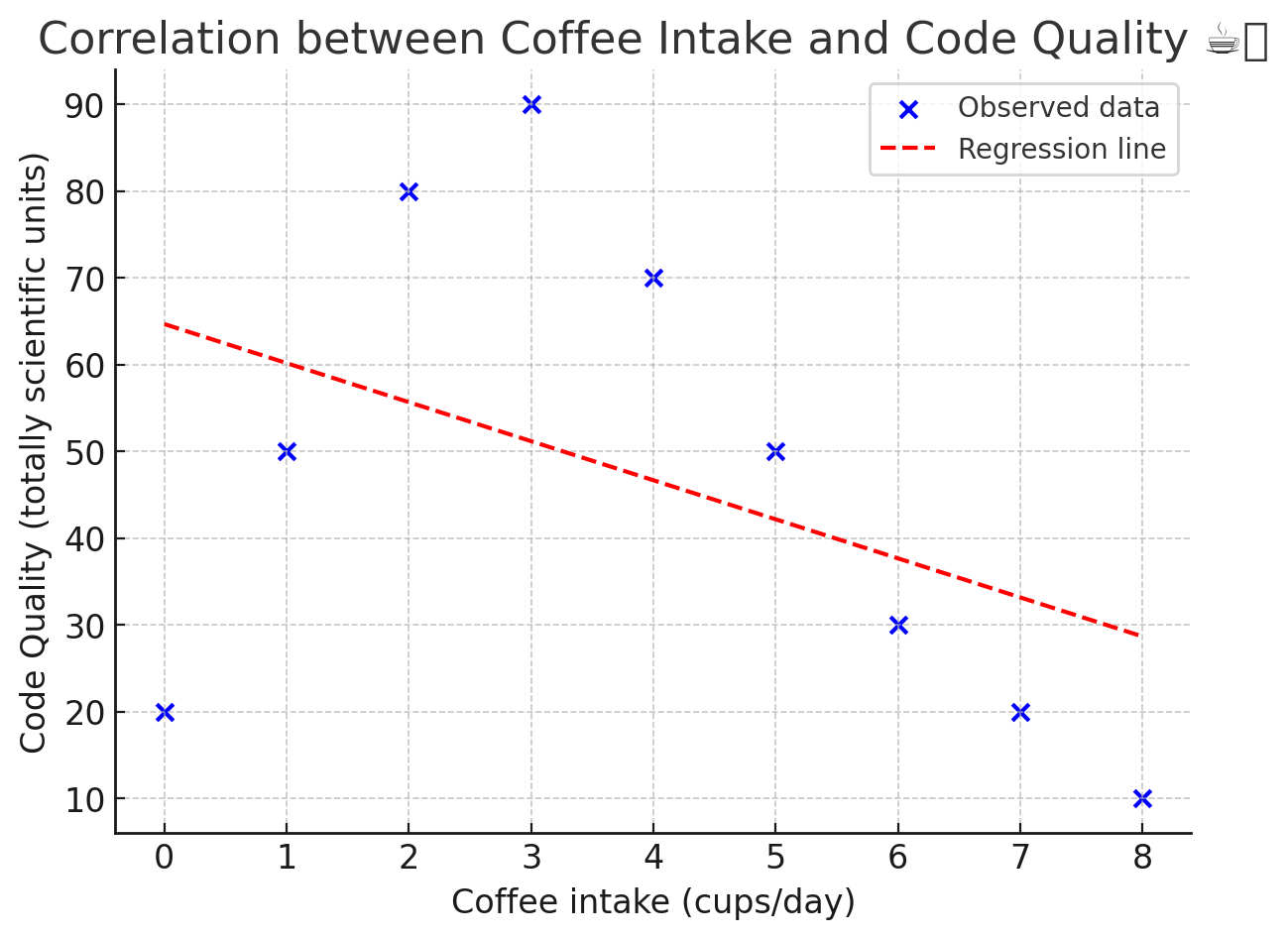 So what is linear regression, why didn't it work and what can I try to make it work?
So what is linear regression, why didn't it work and what can I try to make it work?
Linear regression models the relationship between coffee cups and code quality by fitting a straight line that best predicts the outcome. Unfortunately there is no straight line to fit, otherwise, I'd become a genius as I consume oceans of coffee. Au contraire, after the 4th or 5th cup I start getting jittery and my code turns into ravings of a madman.
The more appropriate fit is a parabole
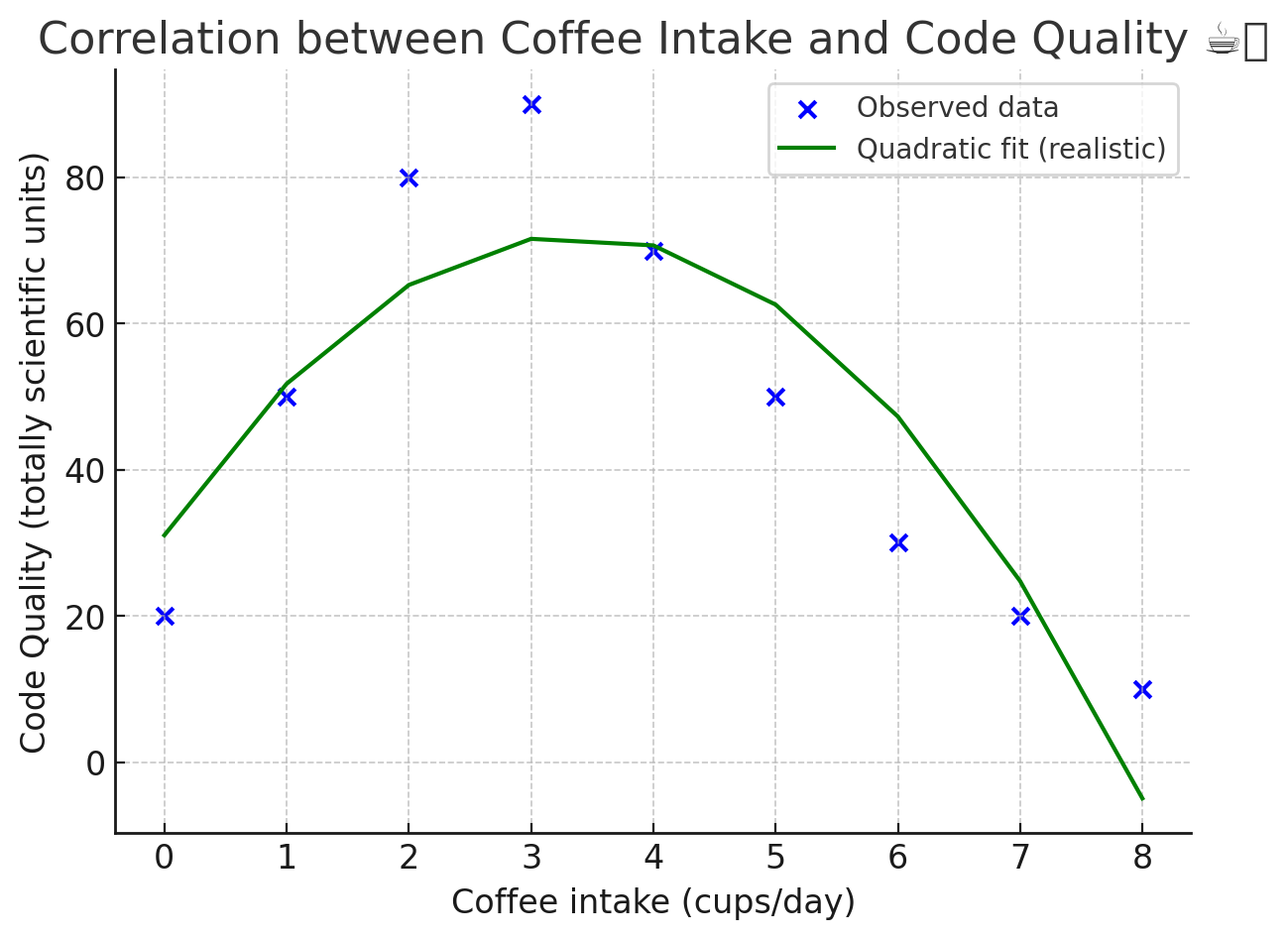 This is still a regression.
This is still a regression.
So what is Machine Learning? How is it (Un)Supervised and how do we go from predicting the optimal amount of coffee cups to ChatGPT drawing your weekly workout plans (in Hungarian if you wish to)
Machine Learning is a process of building models that learn patterns from data without being given explicit programming rules. The model encapsulates the function that calculates outputs from given inputs. The process of finding that function is called training; the process of using it to predict new values is called inferencing. In ML inputs are called features and outputs are called labels.
Supervised Machine Learning includes both features and labels. Some examples of Supervised ML include:
- Regression: figure out how many cold drinks will sell depending on the weather. The observations will include features like: temperature (and maybe hours above a certain temperature, rain, etc). You start by trying to find a function y = ax + b that will fit the elements the closest - your goal is to minimize the difference between predicted values and the actual ones.
- Polynomial regression (when the straight line doesn't work)
- Classification
- Binary: is the element something or not, i.e. is my mole cancerous? Now the function you're trying to fit is a sigmoid (so values close to 0 or 0)
- Multiclass: how can I classify elements in one of many categories?
- Do I do binary over and over again? (OvR)
- Do I try a multinomial algorithm that will create a single function with multiple outputs like softmax?
- Decision Trees: can I classify elements by multiple else-ifs?
- Ensemble Methods: What if one method is not enough and I want to boost it?
Unsupervised ML only gives you the features and let's the computer figure out the patterns, like:
- Clustering: grouping things together, i.e. k-Means Clustering
- Dimensionality Reduction simplifies data while keeping patterns, i.e. PCA or UMAP
- Association Rule Learning finds relations between variables, like in shopping analysis: "people who bought scary ginger blue eyed dolls, later bought knives and killed their whole family"
Deep Learning adds Layers to this but this is subject for another deep dive.